前言:
昨天的文章介紹了在1956-1974年人工智慧黃金年代發展及搜索式推理,今天的內容要介紹的是自然語言處理(Natural Language Processing),讓我們繼續看下去吧。
自然語言處理(Natural Language Processing):
甚麼是自然語言?
先講述一下甚麼是自然語言,所謂的自然語言是指中文、英文、日文、西班牙文這些語言。自然語言處理(Natural Language Processing)是隸屬於人工智慧的一個項目,此領域探討如何處理及運用自然語言,其中包括:有認知、理解、生成等部分。而電腦端的處理主要是能把輸入或接收到的訊息轉換成有意義的編碼符號。
這個領域占了人工智慧中非常重要的一部分,也是發展的重點項目之一。
自然語言處理在AI中遇到的問題
舉個簡單的例子:當我們要設計一個醫療照護系統時,有一個病人對著機器說了一句:我肚子好痛,但機器卻只給他:你為甚麼肚子痛? 自然語言處理主要的目的就是不要讓這種空泛的回答出現,而是真正有用有幫助的反饋。而在實務上操作上會遇到的困難就是因為機器通常都是照著模組的指示去輸出,機器本身並不知道自己在說甚麼也不具有思考能力,這就是人工智慧最大的困難。
因此在處理語言問題時,不能只是丟給機器:遇到甚麼問題要做甚麼反應,而是找出遇到這類問題時真正的意義,透過資料大數據統計的方式便比較能夠貼切地做到這點。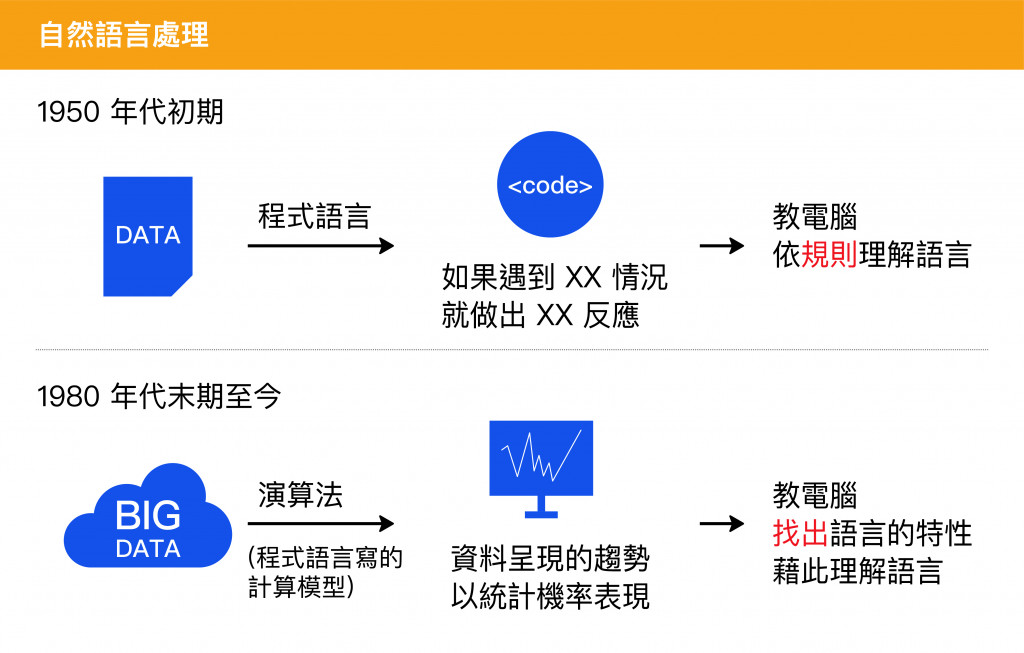
如何訓練AI更快速理解中文詞語?
訓練語文能力最重要的一項處理方法莫過於是深度學習 (Deep Learning)了,而學生用深度學習的方法提出了一個**「詞向量」**概念能夠解決大量的統計分類文字,主要用特性向量的概念解決。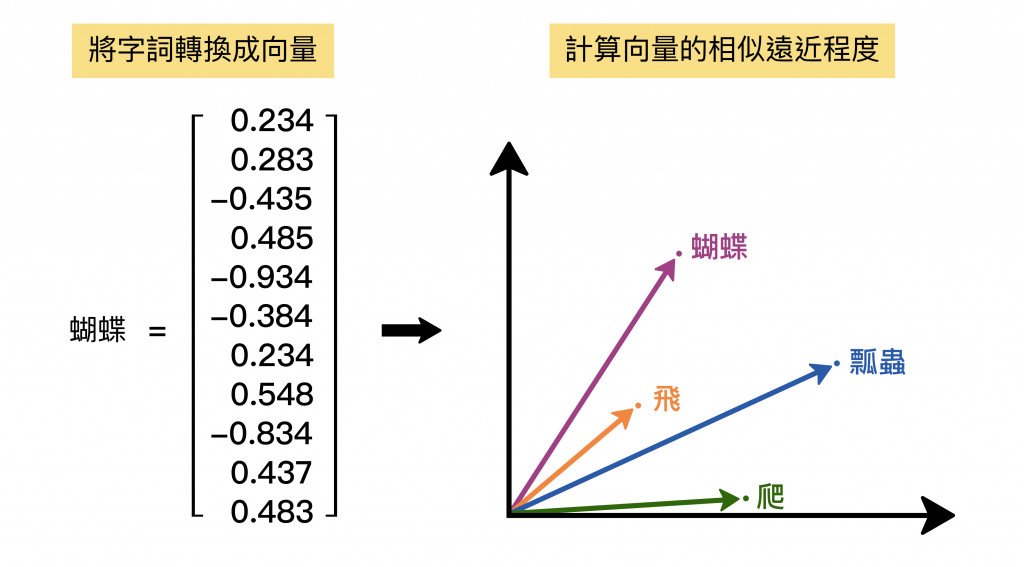
舉例來說,「蝴蝶」、「瓢蟲」、「爬」是不同的三個詞彙,改成詞向量思考方式,「蝴蝶」和「瓢蟲」的向量距離就會比較近,「蝴蝶」和「爬」的向量距離就會比較遠。
隨著訓練的文本越來越多,電腦可以自動調整各個詞彙的向量,解決訓練data不足的問題,也可以提升電腦的抽象化思考。
資料來源:
https://aiacademy.tw/what-is-nlp-natural-language-processing/
https://zh.wikipedia.org/zh-tw/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD%E5%8F%B2
https://zh.wikipedia.org/zh-tw/%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86


 iThome鐵人賽
iThome鐵人賽